Web Crawling
Now, it’s time to introduce you to the unsung heroes of the web – the web crawlers, often referred to as spiders or bots.
1. The Role of Web Crawlers (Spiders or Bots)
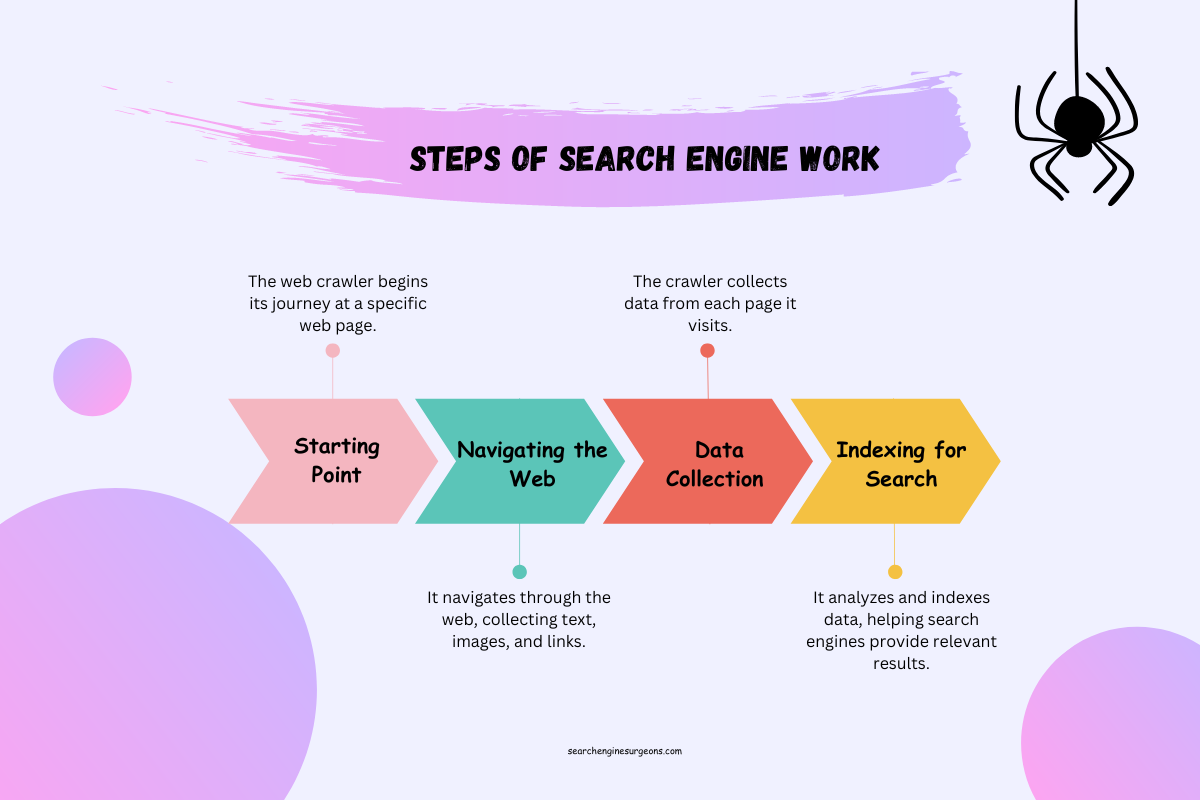
Let’s start with the stars of the show – web crawlers, often affectionately called spiders or bots. These digital creatures are the unsung heroes of the internet, tirelessly weaving their intricate web of information. Imagine them as the explorers of the digital age, venturing into the depths of the web to discover and catalog web pages. They follow links from one page to another, much like how you explore the internet by clicking on links that pique your curiosity. It’s their mission to find, record, and bring back data to the search engine’s lair.
But remember, these bots aren’t just interested in any old web page; they’re on a quest for quality and relevance. They’re like discerning food critics at a bustling food festival, searching for the tastiest treats to recommend.
2. How Web Crawlers Navigate the Internet
Now, let’s unravel the mystery of how these web crawlers navigate the vast labyrinth of the internet. It’s a bit like solving a maze, but instead of walls and dead ends, they encounter a myriad of web pages, each with its unique structure and content. They use clever algorithms to determine the most efficient path, like a GPS guiding you through a bustling city. They map out the terrain, find shortcuts, and ensure no stone (or web page) is left unturned.
3. Challenges and Limitations in Web Crawling
Ah, but here’s where things get interesting – the challenges and limitations. Just like Indiana Jones navigating treacherous traps, web crawlers face obstacles. Some websites put up barriers, like requiring user logins, making it hard for bots to access their content. Others might have endless loops of links that confuse our dear crawlers, causing them to spin their digital wheels in frustration.
Plus, the sheer size of the internet poses a challenge. Imagine trying to explore the entire world in a day; it’s just not possible. Similarly, web crawlers can’t crawl every page in existence, so they focus on the most important and frequently updated ones.
Indexing
Imagine the internet as a colossal library with billions of books. Now, picture search engines as the librarians, meticulously organizing this digital maze. Now, We’re going to unveil the magic behind building an index of web pages, the clever data structures they use, and how they store and retrieve this treasure trove of information.
1. Building an Index of Web Pages
Creating an index of web pages is like compiling a library catalog, but on a gargantuan scale. Think of it as a diligent librarian systematically cataloging books by title, author, and subject. Search engines do something similar but with web pages. They analyze the content, extract keywords, and classify each page by topic.
Why is this important, you ask? Well, it’s the only way to make sense of the internet’s chaos. Without this organization, finding relevant information would be like hunting for a needle in a haystack while blindfolded.
2. Data Structures Used in Indexing
Now, let’s dive into the technical side without getting lost in jargon. Think of data structures as the librarian’s filing cabinet. Search engines use specialized data structures to efficiently store and retrieve information from their colossal index. One such structure is the inverted index, which is a bit like an index in the back of a book, listing all the keywords and where they can be found. This makes searching lightning-fast.
3. Storage and Retrieval of Indexed Information
Imagine you walk into a library, and the librarian instantly hands you the exact book you’re looking for. That’s the magic of efficient storage and retrieval, and search engines have mastered it. They use powerful servers and databases to store and quickly fetch indexed information. When you search for “best pizza in town,” the search engine consults its index, finds the most relevant pages, and serves them up to you in the blink of an eye.
But remember, this digital library is colossal, and maintaining it is a never-ending task. Web pages are constantly changing, new ones emerge, and old ones disappear. It’s like trying to organize a library that’s in a state of perpetual chaos, but search engines are up to the task.
Querying and Ranking
Ah, the moment you type those words into that innocent-looking search bar, a world of digital possibilities unfolds before you. But have you ever wondered how search engines take your seemingly random queries and magically turn them into a list of spot-on results? It’s a bit like deciphering a cryptic treasure map, and in this chapter, we’re diving headfirst into the fascinating world of user query processing, complete with a few surprises!
1. Parsing and Understanding User Queries
When you type, “How to bake the perfect chocolate chip cookies?” into that little search box, you’re essentially sending a digital message to the search engine, saying, “Hey, I’m looking for tips on baking cookies.” But how does it know that? That’s where the magic begins.
The search engine’s first task is parsing, which is a fancy way of saying it breaks down your sentence into understandable chunks. Think of it as a chef breaking down a complex recipe into individual ingredients. It looks for keywords, like “bake,” “perfect,” “chocolate chip,” and “cookies.” Each word helps the search engine understand your intent.
2. Query Expansion and Correction
But here’s where it gets even more intriguing. What if you made a typo and wrote, “How to make the perfect chocolate chip cookes?” Don’t worry; the search engine’s got your back! It employs a nifty trick called query expansion and correction. It sees your typo, recognizes that “cookes” should be “cookies,” and voila, it corrects it for you. Just like having a helpful friend who fixes your mistakes before you even notice.
So, the next time you type something into that search bar, remember that it’s not just a simple text box; it’s your gateway to a world of digital understanding and search engine magic.
Ranking algorithms
Imagine this: You’re at a bustling marketplace, surrounded by countless vendors vying for your attention. Each stall offers something different, but you’re looking for that one perfect item. That’s precisely what’s happening behind the scenes when you search on the internet. Let’s get deep into the world of ranking algorithms, the puppet masters pulling the strings to ensure you find exactly what you’re looking for.
1. Overview of Major Ranking Algorithms (e.g., PageRank, TF-IDF)
Let’s pull back the curtain on these digital puppeteers. Ranking algorithms are the secret sauce that makes search engines work. They decide which web pages deserve the limelight and which ones remain in the shadows. Imagine them as judges at a talent show, but instead of tap dancing or singing, web pages are showcasing their relevance.
One heavyweight in this algorithmic arena is PageRank, created by the brilliant minds behind Google. It evaluates the importance of a web page based on the number and quality of links pointing to it. Think of it as web page popularity contest, with the most popular ones getting top billing.
Then there’s TF-IDF (Term Frequency-Inverse Document Frequency), a mouthful of a name but a powerful tool. It assesses how often specific words appear in a document compared to their frequency across all documents. In simpler terms, it helps search engines understand which words are crucial in a particular context. It’s like knowing that in a pizza recipe, “cheese” and “crust” are more important than “flour” and “salt.”
2. Importance of User Intent in Ranking
But hold on, it’s not just about popularity and word frequency; user intent plays a pivotal role. Search engines aim to be mind-readers, deciphering what you really want. For instance, if you search for “apple,” do you mean the fruit or the tech giant? The ranking algorithm needs to figure that out, so it can serve up the right results. It’s like having a waiter who knows exactly what pizza toppings you crave without you saying a word.
3. Personalization of Search Results
And here’s the cherry on top: personalization. Search engines are getting better at understanding your unique preferences. They consider your past searches, location, and even the time of day to tailor your results. So, if you’re searching for “best pizza” in New York City, you won’t get recommendations for a pizzeria in Tokyo. It’s like having a pizza chef who knows your taste buds inside out.
So, the next time you see those search results pop up, know that a complex dance of algorithms is at play, evaluating web pages, understanding your intent, and personalizing the experience just for you.